Special Session 7: Cloud Services Organization

Goals
We hope to provide you with the following understanding of:
- what are the "service levels" and the related responsibilities for different kinds of cloud resources, and how does that help you choose a service
- what options for interacting with cloud services
- Understand difference between the cloud manager and resource you've created
- Know how to use program to automate the creation and deletion of cloud resources
- How to find basic cost estimates
Introduction
We might think of using cloud computing in 3 areas: using the resources (which is our real goal), definining and creating these resources, and manageing them.
We may need a virtual machine to run our program to calculate or analyze our data, but we need to determine the properties of that virtual machine and create it first. Surrounding all of that is how we interact with the cloud service to do that, how we estimate and observe the costs, manage and identify all the other components a cloud VM needs, and make it as secure as possible.
I'm lumping all of these last pieces into 'managing' cloud resources. It may be the most boring of all the topics. The concepts may cover any resource you create in the cloud, and in general apply to all cloud service providers. However the details of how you do it are very specific to each cloud vendor. In fact the methods may be convoluted or less than straightforward, so there are many companies that provide additional tools just to manage cloud resources in a more consistent or easier way than the cloud providers allow you
Service Level Model of Cloud
The NIST definition of cloud computing defines service models, but what does "X as a service" actually mean, and where are the lines drawn? Like the species concept in biology, it's not always cut and dried, but can be thought of as a spectrum
- Infrastructure (aaS): Nuts and bolts, DIY, Lego. You need understanding of computing architecture as these services
- Everything in between: Platforms or pre-configured and managed infrastructure
- Software (aaS): Little to no configuration is needed but these system may be programmable and integrated with other services. E.g. Office 365, Google Drive
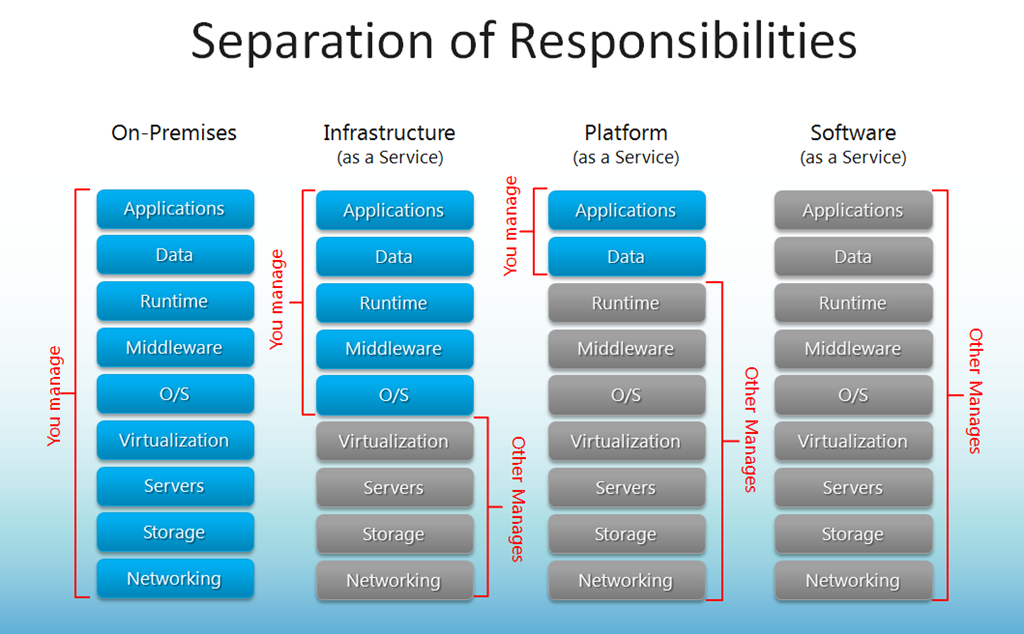
The sweet-spot for researchers who do not have time to aquire the expertise to manage low-level infrastructure and need something more flexible and programmable than Software, are the platforms. These are often more expensive than DIY infrastruture, but are faster to provision and provide security controls.
Cloud "Services" and the Packaging of Open Source Systems
Case Study on Open Source system as Cloud service: **MySQL **
Open source, free Relational database, e.g. SQL. Relational databases store tabular, linked data. Used by some bioinformatics packages (e.g. https://orthomcl.org/orthomcl/app) and millions of websites.
- project: https://www.mysql.com/products/community/ and https://mariadb.org/
- DIY on Azure instructions (eg Iaas): someone's DIY Mysql - don't follow these, they are old and may not work, just an example of the steps involved
- Azure MySQL Service (e.g PaaS): Azure Database for MySQL
- AWS MySQL Service: Amazon RDS for MySQL
- Google MySQL Service Cloud SQL
-
other companies, such as Aiven for MySQL
-
Spin-offs: Amazon also offers AWS Aurora which is a cloud scale database service that is MySQL-compatible see Amazon Aurora Paper
What would a "SaaS" offering for your research look like? A "Google Docs" for your databases? How about a "PasS" that you could build? Would it be reproducible by anyone doing the kind of research you do?
Costs
Cautionary Tale: Google Cloud Charged Me $1000 For This Mistake by Kunal Vaidya on Medium. *tl;dr: he forgot to turn off a service even though he was no longer using it. Good news it, Google does grant 1-time forgiveness if you can prove you are using the service to learn about it (e.g. you are student). *
Interfaces
In session one we talked about the client/server model of computing which is so ubiquotous is seems like the only model of computing.
The core of the cloud model is that "everything has an API" or Application Programming Interface: the commands that can be used for code-to-code interaction.
Reading:
- Interfacing with Cloud Services
- About the Microsoft Resource Manager: https://learn.microsoft.com/en-us/azure/azure-resource-manager/management/overview
Acivity:
Note the "Interface" is for interacting with Azure to manage resources. The resources them selves will have their OWN interface.
Moving Data
Staying Organized in Azure
You've seen that using the web portal to create a virtual machine creats a dozen resources. Then you may have other resources (e.g. a storage account) you want to connect to them. How do you keep them all straight?
Naming things
Microsoft suggestion for creating names: https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/ready/azure-best-practices/resource-naming
Why do names have an "Environment" element?
IT professionals tend to think of the world in two ways: the stuff I'm doing to try things, and the stuff I've done that now the world can use. That's because once a system is open or connected to a public interface, they have to keep it running. Some use the term "production" or in-production.
- development (dev): in progress experimental versions, never intended for public use, strictly for our use
- test: optional state, the system is as close to finished as possible and given to staff to do formal testing to ensure it's ready for publication
- production (prod): final version released to the public
- optional "preview" or "beta" : companies use this to get themselves off the hook. It's not really done and they may just remove the service, no guarantees.
A production environment is deploying resources so that they are unchanged, stable and don't have down time. A "site reliability engineer" (SRE) is paid to avoid downtime.
Why do they call out 'region' in this naming scheme? For global web companies, they may deploy duplicate resources in many regions. In addition resources that interaction should be in the same region, e.g. a storage acccount and a VM that uses it should be in the same region to keep the connection fast.
using Azure 'Tags'
- Optional: Short note about Using Azure Tags for Organization ( Pat Bills, MSU)
- "Use tags to organize your Azure resources and management hierarchy" from Microsoft
Microsoft suggested naming scheme for Azure resources
Monitoring
You want to keep an eye on the resources you create: how healthy are they, are they performing as expected? Is there some problem that makes them slow or unresponsive? This is especially true of servers, created by IT staff, that others are using that need to stay up and running. For us as researchers creating resources to do our calculations, we want to know how long it's taking and hence how much will it cost? Do we need to add more power to get it to work?
This is an esoteric topic and is really specific to each type of service, but it's something to consider as 1) you may need to engage in a resource outside of the azure portal (e.g. in a VM, log-in and check the performance with standard tools like 'top' in Linux and the task manger in Windows) 2) create (and pay for!) yet another cloud resource for collective and 'managed' monitoring.
Why use cloud monitoring at all? If you were running a bunch of your own computers in your lab, you would just sit down and check on them using tools the operating system provided. In many systems you open and read the 'logs' or text files with a stream of the events and times they occured.
Machines in the cloud provide new challenges. An obvious one is to be able to see statistics for many resources at once. How then does Azure collect data from each machine into central place and then let you browse it? A second challenge is, what happens to that information for a virtual machine that has crashed and is unresponsive, or has been intentionally turned off and deleted?
Monitoring Examples
For Azure virtual machines, Azure offers "Azure Monitor". Using it is completely optional and I don't have activities related to this service. If for your project you are working with a group of VM's, you are interested in performance, or you need performance information because your analysis is not completing then I would investigate this service.